Il campionamento delle quote È un modo non probabilistico di prelevare dati da un campione assegnando quote per strati. Le quote devono essere proporzionali alla frazione che questo strato rappresenta rispetto alla popolazione totale e la somma delle quote deve essere uguale alla dimensione del campione.
Il ricercatore è colui che decide quali saranno i gruppi o gli strati, ad esempio, può dividere una popolazione in uomini e donne. Un altro esempio di strati sono le fasce di età, ad esempio da 18 a 25, da 26 a 40 e da 40 in poi, che possono essere etichettate come segue: giovani, adulti e anziani.

È molto conveniente sapere in anticipo quale percentuale della popolazione totale rappresenta ogni strato. Quindi viene scelta una dimensione del campione statisticamente significativa e vengono assegnate quote proporzionali alla percentuale di ogni strato rispetto alla popolazione totale. La somma delle quote per strato deve essere uguale alla dimensione totale del campione.
Infine si procede a prendere i dati delle quote assegnate a ciascuna falda, scegliendo i primi elementi che completano la quota.
È proprio a causa di questo modo non casuale di scegliere gli elementi che questo metodo di campionamento è considerato non probabilistico..
Indice articolo
Segmenta la popolazione totale in strati o gruppi con alcune caratteristiche comuni. Questa caratteristica sarà preventivamente decisa dal ricercatore statistico che conduce lo studio..
Determina quale percentuale della popolazione totale rappresenta ciascuno degli strati o gruppi scelti nel passaggio precedente.
Stimare una dimensione del campione statisticamente significativa, secondo i criteri e le metodologie della scienza statistica..
Calcola il numero di elementi o quote per ogni strato, in modo che siano proporzionali alla percentuale che ciascuno rappresenta rispetto alla popolazione totale e alla dimensione totale del campione..
Prendi i dati degli elementi in ogni strato fino a completare la quota corrispondente a ciascuno strato.
Supponi di voler conoscere il livello di soddisfazione con il servizio di metropolitana in una città. Precedenti studi su una popolazione di 2000 persone hanno stabilito che il 50% degli utenti lo è giovani tra i 16 ei 21 anni, il 40% lo è Adulti tra i 21 ei 55 anni e solo il 10% degli utenti lo ha maggiore più di 55 anni.
Sfruttando i risultati di questo studio, viene segmentato o stratificato in base all'età degli utenti:
-Giovani: cinquanta%
-Adulti: 40%
-Maggiore: 10%
Poiché il budget è limitato, lo studio deve essere applicato a un piccolo campione, ma statisticamente significativo. Viene scelto un campione di 200 persone, ovvero l'indagine sul livello di soddisfazione verrà applicata a 200 persone in totale.
È ora necessario determinare la quota o il numero di indagini per ogni segmento o strato, che deve essere proporzionale alla dimensione del campione e alla percentuale per strato..
La quota per il numero di indagini per strato è la seguente:
Giovani: 200 * 50% = 200 * (50/100) = 100 sondaggi
Adulti: 200 * 40% = 200 * (40/100) = 80 sondaggi
Maggiore: 200 * 10% = 200 * (10/100) = 20 sondaggi
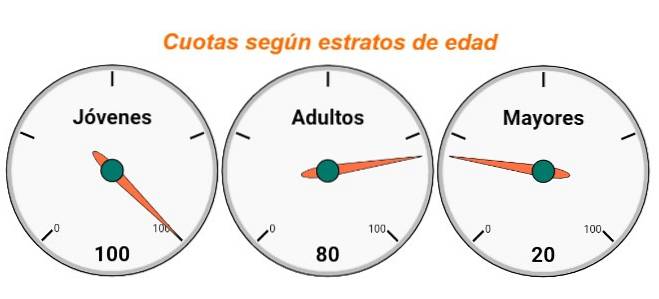
Si noti che la somma delle quote deve essere uguale alla dimensione del campione, cioè uguale al numero totale di sondaggi che verranno applicati. Quindi le indagini vengono superate fino al raggiungimento delle quote per ogni strato.
È importante notare che questo metodo è molto meglio che prendere tutti i sondaggi e trasmetterli alle prime 200 persone che compaiono, perché secondo i dati precedenti, è molto probabile che lo strato di minoranza venga escluso dallo studio.
Affinché il metodo sia applicabile, è necessario un criterio per la formazione degli strati, che dipende dall'obiettivo dello studio..
Il campionamento delle quote è adatto quando si desidera conoscere le preferenze, differenze o caratteristiche per settori per indirizzare campagne specifiche in base allo strato o al segmento.
Il suo utilizzo è utile anche quando per qualche motivo è interessante conoscere le caratteristiche o gli interessi di settori minoritari, o quando non si vuole lasciarli fuori dallo studio.
Per essere applicabile, è necessario conoscere il peso o il significato di ogni strato rispetto alla popolazione totale. È molto importante che questa conoscenza sia affidabile, altrimenti si otterranno risultati errati.
-Riduce i tempi di studio, perché le quote per strato sono generalmente piccole
-Semplifica l'analisi dei dati.
-Riduce al minimo i costi perché lo studio viene applicato a campioni piccoli ma ben rappresentativi della popolazione totale.
-Poiché gli strati sono definiti a priori, è possibile che alcuni settori della popolazione siano esclusi dallo studio.
-Stabilendo un numero limitato di strati, è possibile che i dettagli vengano persi nello studio.
-Evitando o incorporando come parte di un altro uno strato può portare a conclusioni errate nello studio.
-Rende impossibile stimare l'errore massimo di campionamento.
Vuoi fare uno studio statistico su livello di ansia in una popolazione di 2000 persone.
Il ricercatore che dirige la ricerca intuisce che le differenze nei risultati devono essere trovate a seconda dell'età e del sesso. Per questo motivo, decide di formare tre fasce di età così indicate: First_Age, Second_Age Y Third_Age. Per quanto riguarda il segmento sesso si definiscono i due tipi usuali: Maschio Y Femminile.
Definisce First_Age, quello tra i 18 ei 25 anni, Second_Age quella tra i 26 ei 50 anni e finalmente Third_Age quella tra i 50 e gli 80 anni.
Analizzando i dati della popolazione totale è necessario:
Il 45% della popolazione appartiene al First_Age.
Il 40% è nel Second_Age.
Infine, solo il 15% della popolazione in studio appartiene al Third_Age.
Utilizzando una metodologia appropriata, non dettagliata qui, si determina che un campione di 300 persone è statisticamente significativo.
Il passaggio successivo sarà quindi trovare le quote corrispondenti per il segmento Età, che viene fatto come segue:
Prima_età: 300 * 45% = 300 * 45/100 = 135
Seconda_età: 300 * 40% = 300 * 40/100 = 120
Terza_età: 300 * 15% = 300 * 15/100 = 45
Si è verificato che la somma delle quote dà la dimensione totale del campione.
Finora il segmento non è stato preso in considerazione sesso della popolazione, di questo segmento sono già stati definiti due strati: Femminile Y Maschio. Ancora una volta dobbiamo analizzare i dati della popolazione totale, che forniscono le seguenti informazioni:
-Il 60% della popolazione totale è di sesso Femminile.
-Nel frattempo, il 40% della popolazione da studiare appartiene al sesso Maschio.
È importante notare che le precedenti percentuali relative alla distribuzione della popolazione in base al sesso non tengono conto dell'età..
Dato che non sono disponibili ulteriori informazioni, si supporrà che queste proporzioni in termini di sesso siano equamente distribuite nei 3 strati di Età che sono stati definiti per questo studio. Con queste considerazioni, procediamo ora a stabilire le quote per Età e Sesso, il che significa che ora ci saranno 6 sottostrati:
S1 = First_Age e Femmina: 135 * 60% = 135 * 60/100 = 81
S2 = First_Age e Male: 135 * 40% = 135 * 40/100 = 54
S3 = Second_Age e Femmina: 120 * 60% = 120 * 60/100 = 72
S4 = Second_Age e Male: 120 * 40% = 120 * 40/100 = 48
S5 = Third_Age and Female: 45 * 60% = 45 * 60/100 = 27
S6 = Third_Age e Male: 45 * 40% = 45 * 40/100 = 18
Una volta stabiliti i sei (6) segmenti e le quote corrispondenti, vengono predisposte 300 indagini che verranno applicate in base alle quote già calcolate..
Le indagini verranno applicate come segue, verranno effettuate 81 indagini e intervistate le prime 81 persone che si trovano nel segmento S1. Quindi è fatto allo stesso modo con i restanti cinque segmenti.
La sequenza dello studio è la seguente:
-Analizza i risultati del sondaggio, che vengono poi discussi, analizzando i risultati per segmento.
-Effettua confronti tra i risultati per segmento.
-Infine, sviluppa ipotesi che spieghino le cause di questi risultati..
Nel nostro esempio in cui applichiamo il campionamento per quote, la prima cosa da fare è stabilire le quote e poi svolgere lo studio. Naturalmente, queste quote non sono affatto stravaganti, perché sono state basate su precedenti informazioni statistiche sulla popolazione totale..
Se non si dispone di informazioni preventive sulla popolazione in studio, è preferibile invertire la procedura, ovvero definire prima la dimensione del campione e una volta stabilita la dimensione del campione, procedere con l'applicazione dell'indagine in modo casuale.
Un modo per garantire la casualità sarebbe utilizzare un generatore di numeri casuali e interrogare i dipendenti il cui numero di dipendenti corrisponde a quello del generatore casuale..
Una volta che i dati sono disponibili, e poiché l'obiettivo dello studio è quello di vedere i livelli di ansia in base agli strati di età e sesso, i dati vengono separati secondo le sei categorie che avevamo definito in precedenza. Ma senza fissare alcuna tariffa preventiva.
È per questo motivo che il metodo di campionamento casuale stratificato è considerato un metodo probabilistico. Nel frattempo lui campionamento delle quote precedentemente stabilito n.
Tuttavia, se le quote sono stabilite con informazioni basate sulle statistiche della popolazione, si può affermare che il metodo di campionamento delle quote è approssimativamente probabilistico.
Viene proposto il seguente esercizio:
In una scuola secondaria vuoi fare un sondaggio sulla preferenza tra lo studio delle scienze o quello delle materie umanistiche.
Supponiamo che la scuola abbia un totale di 1000 studenti raggruppati in cinque livelli in base all'anno di studio. È noto che ci sono 350 studenti nel primo anno, 300 nel secondo, 200 nel terzo, 100 nel quarto e infine 50 nel quinto anno. È anche noto che il 55% degli studenti della scuola sono maschi e il 45% femmine..
Determinare gli strati e le quote per strato, al fine di conoscere il numero di indagini da applicare in base all'anno di studio e ai segmenti di sesso. Supponiamo inoltre che il campione sia il 10% della popolazione studentesca totale..



Nessun utente ha ancora commentato questo articolo.