Il voto di classe, Conosciuto anche come punto medio, è il valore che si trova al centro di una classe, che rappresenta tutti i valori che si trovano in quella categoria. Fondamentalmente, il voto di classe viene utilizzato per calcolare alcuni parametri, come la media aritmetica o la deviazione standard..
Quindi il segno di classe è il punto medio di qualsiasi intervallo. Questo valore è molto utile anche per trovare la varianza di un insieme di dati già raggruppati in classi, che a sua volta ci permette di capire quanto lontani dal centro si trovano questi dati specifici.

Indice articolo
Per capire cos'è un voto di classe, è necessario il concetto di distribuzione di frequenza. Dato un insieme di dati, una distribuzione di frequenza è una tabella che divide i dati in un numero di categorie chiamate classi..
Detta tabella mostra la quantità di elementi che appartiene a ciascuna classe; quest'ultimo è noto come frequenza.
In questa tabella, parte delle informazioni che otteniamo dai dati viene sacrificata, poiché invece di avere il valore individuale di ogni elemento, sappiamo solo che appartiene a quella classe.
D'altra parte, otteniamo una migliore comprensione del set di dati, poiché in questo modo è più facile apprezzare modelli stabiliti, il che facilita la manipolazione di tali dati..
Per creare una distribuzione di frequenza, dobbiamo prima determinare il numero di classi che vogliamo prendere e scegliere i loro limiti di classe..
Scegliere quante classi prendere dovrebbe essere conveniente, tenendo conto che un numero ridotto di classi può nascondere informazioni sui dati che vogliamo studiare e una molto grande può generare troppi dettagli non necessariamente utili.
I fattori di cui dobbiamo tenere conto nella scelta di quante lezioni prendere sono diversi, ma tra questi spiccano due: il primo è quello di tenere conto di quanti dati dobbiamo considerare; il secondo è sapere quanto è ampio il range della distribuzione (cioè la differenza tra l'osservazione più grande e quella più piccola).
Dopo aver definito le classi, procediamo a contare quanti dati esistono in ogni classe. Questo numero è chiamato frequenza delle lezioni ed è indicato con fi.
Come abbiamo detto in precedenza, abbiamo che una distribuzione di frequenza perde le informazioni che provengono individualmente da ogni dato o osservazione. Per questo motivo si cerca un valore che rappresenti l'intera classe a cui appartiene; questo valore è il segno di classe.
Il marchio di classe è il valore fondamentale rappresentato da una classe. Si ottiene sommando i limiti dell'intervallo e dividendo questo valore per due. Potremmo esprimerlo matematicamente come segue:
Xio= (Limite inferiore + Limite superiore) / 2.
In questa espressione xio denota il marchio della i-esima classe.
Dato il seguente insieme di dati, fornire una distribuzione di frequenza rappresentativa e ottenere il punteggio delle classi corrispondenti.

Poiché i dati con il valore numerico più alto sono 391 e il più basso è 221, abbiamo che l'intervallo è 391-221 = 170.
Sceglieremo 5 classi, tutte con la stessa dimensione. Un modo per scegliere le classi è il seguente:

Nota che ogni dato è in una classe, questi sono disgiunti e hanno lo stesso valore. Un altro modo per scegliere le classi è considerare i dati come parte di una variabile continua, che potrebbe raggiungere qualsiasi valore reale. In questo caso possiamo considerare classi del modulo:
205-245, 245-285, 285-325, 325-365, 365-405
Tuttavia, questo modo di raggruppare i dati può presentare alcune ambiguità al limite. Ad esempio, nel caso di 245, sorge la domanda: a quale classe appartiene, la prima o la seconda?
Per evitare questa confusione, viene stabilita una convenzione sull'endpoint. In questo modo, la prima classe sarà l'intervallo (205,245], la seconda (245,285] e così via.

Una volta definite le classi, procediamo al calcolo della frequenza e abbiamo la seguente tabella:
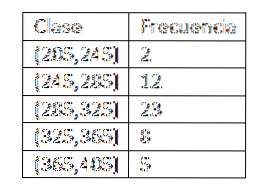
Dopo aver ottenuto la distribuzione di frequenza dei dati, procediamo a trovare i segni di classe di ogni intervallo. In effetti, dobbiamo:
X1= (205+ 245) / 2 = 225
XDue= (245+ 285) / 2 = 265
X3= (285+ 325) / 2 = 305
X4= (325+ 365) / 2 = 345
X5= (365+ 405) / 2 = 385
Possiamo rappresentarlo dal seguente grafico:
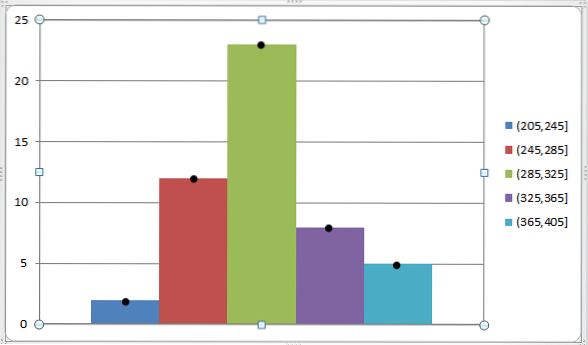
Come accennato in precedenza, il voto di classe è molto funzionale per trovare la media aritmetica e la varianza di un gruppo di dati che sono già stati raggruppati in classi differenti..
Possiamo definire la media aritmetica come la somma delle osservazioni ottenute tra la dimensione del campione. Da un punto di vista fisico, la sua interpretazione è come il punto di equilibrio di un insieme di dati.
Identificare un intero set di dati con un singolo numero può essere rischioso, quindi è necessario tenere conto anche della differenza tra questo punto di pareggio e i dati effettivi. Questi valori sono noti come deviazione dalla media aritmetica e con questi cerchiamo di determinare quanto varia la media aritmetica dei dati..
Il modo più comune per trovare questo valore è tramite la varianza, che è la media dei quadrati delle deviazioni dalla media aritmetica.
Per calcolare la media aritmetica e la varianza di un insieme di dati raggruppati in una classe utilizziamo rispettivamente le seguenti formule:
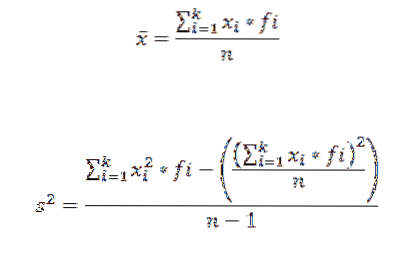
In queste espressioni xio è il marchio i-esimo di classe, fio rappresenta la frequenza corrispondente ek il numero di classi in cui i dati sono stati raggruppati.
Facendo uso dei dati forniti nell'esempio precedente, abbiamo che possiamo espandere un po 'di più i dati della tabella di distribuzione delle frequenze. Ottieni quanto segue:
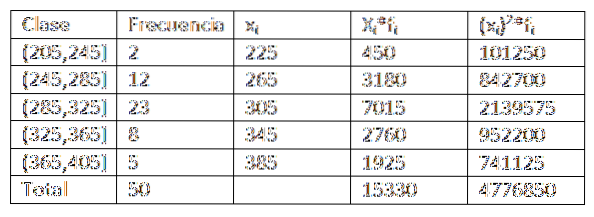
Quindi, sostituendo i dati nella formula, ci resta che la media aritmetica è:
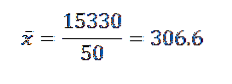
La sua varianza e deviazione standard sono:
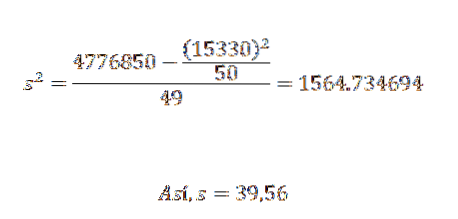
Da ciò possiamo concludere che i dati originali hanno una media aritmetica di 306,6 e una deviazione standard di 39,56..


Nessun utente ha ancora commentato questo articolo.