Il dati non raggruppati sono quelli che, ottenuti da uno studio, non sono ancora organizzati per classi. Quando si tratta di un numero gestibile di dati, di solito 20 o meno, e ci sono pochi dati diversi, possono essere trattati come informazioni non raggruppate e preziose da esso estratte.
I dati non raggruppati provengono così come sono dall'indagine o dallo studio effettuato per ottenerli e quindi mancano di elaborazione. Diamo un'occhiata ad alcuni esempi:

-Risultati di un test del QI su 20 studenti casuali di un'università. I dati ottenuti sono stati i seguenti:
119, 109, 124, 119, 106, 112, 112, 112, 112, 109, 112, 124, 109, 109, 109, 106, 124, 112, 112.106
-Età di 20 dipendenti di una certa caffetteria popolare:
24, 20, 22, 19, 18, 27, 25, 19, 27, 18, 21, 22, 23, 21, 19, 22, 27, 29, 23, 20
-La media del voto finale di 10 studenti in una classe di matematica:
3.2; 3.1; 2.4; 4.0; 3.5; 3.0; 3.5; 3,8; 4.2; 4.9
Indice articolo
Esistono tre proprietà importanti che caratterizzano un insieme di dati statistici, raggruppati o meno, che sono:
-Posizione, che è la tendenza dei dati a raggrupparsi attorno a determinati valori.
-Dispersione, un'indicazione di quanto siano dispersi o dispersi i dati attorno a un dato valore.
-Forma, Si riferisce al modo in cui i dati vengono distribuiti, cosa apprezzata quando si costruisce un grafico degli stessi. Ci sono curve molto simmetriche e anche oblique, a sinistra oa destra di un certo valore centrale.
Per ognuna di queste proprietà esistono una serie di misure che le descrivono. Una volta ottenuti, ci forniscono una panoramica del comportamento dei dati:
-Le misure di posizione più utilizzate sono la media aritmetica o semplicemente la media, la mediana e il modo.
-Intervallo, varianza e deviazione standard sono spesso usati nella dispersione, ma non sono le uniche misure di dispersione..
-E per determinare la forma, la media e la mediana vengono confrontate attraverso il bias, come vedrai tra poco.
-La media aritmetica, noto anche come media e indicato con X, viene calcolato come segue:
X = (x1 + XDue + X3 +… Xn) / n
Dove x1, XDue,…. Xn, sono i dati e n è il loro totale. Nella notazione sommatoria abbiamo:
-Mediano è il valore che compare al centro di una sequenza ordinata di dati, quindi per ottenerlo è necessario prima di tutto ordinare i dati.
Se il numero di osservazioni è dispari, non ci sono problemi a trovare il punto medio dell'insieme, ma se abbiamo un numero pari di dati, i due dati centrali vengono cercati e mediati.
-Moda è il valore più comune osservato nel set di dati. Non sempre esiste, poiché è possibile che nessun valore venga ripetuto più frequentemente di un altro. Potrebbero esserci anche due dati con uguale frequenza, nel qual caso si parla di distribuzione bimodale.
A differenza delle due misure precedenti, la modalità può essere utilizzata con dati qualitativi.
Vediamo come vengono calcolate queste misure di posizione con un esempio:
Supponiamo di voler determinare la media aritmetica, la mediana e il modo nell'esempio proposto all'inizio: l'età di 20 dipendenti di una caffetteria:
24, 20, 22, 19, 18, 27, 25, 19, 27, 18, 21, 22, 23, 21, 19, 22, 27, 29, 23, 20
Il metà viene calcolato semplicemente sommando tutti i valori e dividendo per n = 20, che è il numero totale di dati. In questo modo:
X = (24 + 20 + 22 + 19 + 18 + 27+ 25 + 19 + 27 + 18 + 21 + 22 + 23 + 21+ 19 + 22 + 27+ 29 + 23+ 20) / 20 =
= 22,3 anni.
Per trovare il file mediano devi prima ordinare il set di dati:
18, 18, 19, 19, 19, 20, 20, 21, 21, 22, 22, 22, 23, 23, 24, 25, 27, 27, 27, 29
Poiché si tratta di un numero pari di dati, i due dati centrali, evidenziati in grassetto, vengono presi e mediati. Poiché hanno entrambi 22 anni, la mediana è di 22 anni.
Infine, il moda È il dato che si ripete di più o quello la cui frequenza è maggiore, essendo 22 anni.
L'intervallo è semplicemente la differenza tra il più grande e il più piccolo dei dati e consente di apprezzare rapidamente la variabilità dei dati. Ma a parte, ci sono altre misure di dispersione che offrono maggiori informazioni sulla distribuzione dei dati..
La varianza è indicata come s ed è calcolata dall'espressione:
Quindi, per interpretare correttamente i risultati, la deviazione standard è definita come la radice quadrata della varianza, o anche la deviazione quasi standard, che è la radice quadrata della quasi-varianza:
È il confronto tra la media X e la mediana Med:
-Se Med = media X: i dati sono simmetrici.
-Quando X> Med: inclina a destra.
-E se X < Med: los datos sesgan hacia la izquierda.
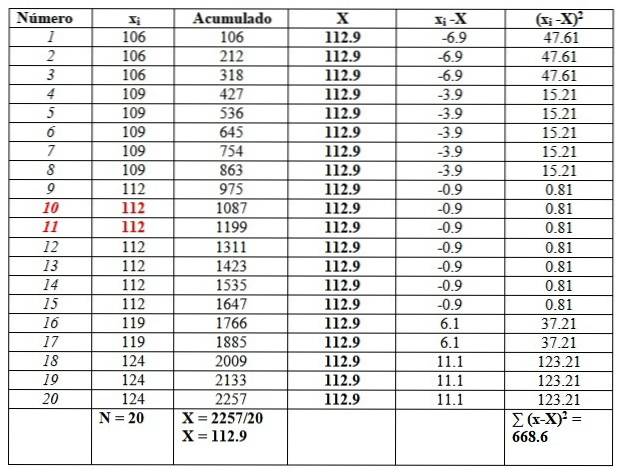
Trova media, mediana, modo, intervallo, varianza, deviazione standard e bias per i risultati di un test del QI eseguito su 20 studenti di un'università:
119, 109, 124, 119, 106, 112, 112, 112, 112, 109, 112, 124, 109, 109, 109, 106, 124, 112, 112, 106
Ordineremo i dati, poiché sarà necessario trovare la mediana.
106, 106, 106, 109, 109, 109, 109, 109, 112, 112, 112, 112, 112, 112, 112, 119, 119, 124, 124, 124
E li metteremo in una tabella come segue, per facilitare i calcoli. La seconda colonna intitolata "Accumulato" è la somma dei dati corrispondenti più quello precedente..
Questa colonna aiuterà a trovare facilmente la media, dividendo l'ultimo accumulato per il numero totale di dati, come si vede alla fine della colonna "Accumulato":
X = 112,9
La mediana è la media dei dati centrali evidenziati in rosso: il numero 10 e il numero 11. Essendo uguali, la mediana è 112.
Infine, la modalità è il valore che si ripete di più ed è 112, con 7 ripetizioni..
Per quanto riguarda le misure di dispersione, la gamma è:
124-106 = 18.
La varianza si ottiene dividendo il risultato finale nella colonna di destra per n:
s = 668,6 / 20 = 33,42
In questo caso, la deviazione standard è la radice quadrata della varianza: √33,42 = 5,8.
D'altra parte, i valori della quasi varianza e della quasi deviazione standard sono:
Sc= 668,6 / 19 = 35,2
Deviazione quasi standard = √35,2 = 5,9
Infine, il bias è leggermente a destra, poiché la media 112,9 è maggiore della mediana 112.


Nessun utente ha ancora commentato questo articolo.