Il dati raggruppati sono quelli che sono stati classificati in categorie o classi, prendendo come criterio la loro frequenza. Questo viene fatto per semplificare la gestione di grandi quantità di dati e stabilirne le tendenze..
Una volta organizzati in queste classi in base alle loro frequenze, i dati costituiscono un file distribuzione di frequenza, da cui si estraggono informazioni utili attraverso le sue caratteristiche.

Ecco un semplice esempio di dati raggruppati:
Supponiamo di misurare l'altezza di 100 studentesse, selezionate tra tutti i corsi di fisica di base di un'università, e di ottenere i seguenti risultati:

I risultati ottenuti sono stati suddivisi in 5 classi, che compaiono nella colonna di sinistra.
La prima classe, tra 155 e 159 cm, ha 6 studenti, la seconda classe 160 - 164 cm ha 14 studenti, la terza classe da 165 a 169 cm ha il maggior numero di membri: 47. Poi la classe continua 170-174 cm con 28 studenti e infine il 175-174 cm con solo 5.
Il numero di membri di ogni classe è precisamente il frequenza o Assoluta frequenza e aggiungendoli tutti, si ottiene il totale dei dati, che in questo esempio è 100.
Indice articolo
Come abbiamo visto, la frequenza è il numero di volte in cui un dato viene ripetuto. E per facilitare i calcoli delle proprietà della distribuzione, come la media e la varianza, vengono definite le seguenti quantità:
-Frequenza cumulativa: si ottiene sommando la frequenza di una classe con la precedente frequenza accumulata. La prima di tutte le frequenze corrisponde a quella dell'intervallo in questione e l'ultima è il numero totale di dati.
-Frequenza relativa: calcolato dividendo la frequenza assoluta di ciascuna classe per il numero totale di dati. E se moltiplichi per 100 hai la frequenza percentuale relativa.
-Frequenza relativa cumulativa: è la somma delle frequenze relative di ciascuna classe con le precedenti accumulate. L'ultima delle frequenze relative accumulate deve essere uguale a 1.
Per il nostro esempio, le frequenze hanno questo aspetto:
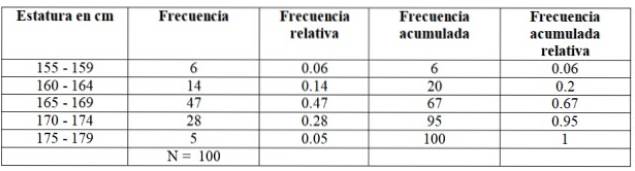
Vengono chiamati i valori estremi di ogni classe o intervallo limiti di classe. Come possiamo vedere, ogni classe ha un limite inferiore e uno superiore. Ad esempio, la prima classe nello studio sulle altezze ha un limite inferiore di 155 cm e un limite superiore di 159 cm..
Questo esempio ha limiti chiaramente definiti, tuttavia è possibile definire limiti aperti: se invece di definire i valori esatti, dì "altezza inferiore a 160 cm", "altezza inferiore a 165 cm" e così via.
L'altezza è una variabile continua, quindi si può considerare che la prima classe inizia effettivamente da 154,5 cm, poiché arrotondando questo valore all'intero più vicino si ottengono 155 cm.
Questa classe copre tutti i valori fino a 159,5 cm, perché dopo questo le altezze vengono arrotondate a 160,0 cm. Un'altezza di 159,7 cm appartiene già alla seguente classe.
I limiti di classe effettivi per questo esempio sono, in cm:
La larghezza di una classe si ottiene sottraendo i confini. Per il primo intervallo del nostro esempio abbiamo 159,5 - 154,5 cm = 5 cm.
Il lettore può verificare che anche per gli altri intervalli dell'esempio l'ampiezza è di 5 cm. Tuttavia, va notato che le distribuzioni possono essere costruite con intervalli di ampiezza diversa.
È il punto medio dell'intervallo ed è ottenuto dalla media tra il limite superiore e il limite inferiore.
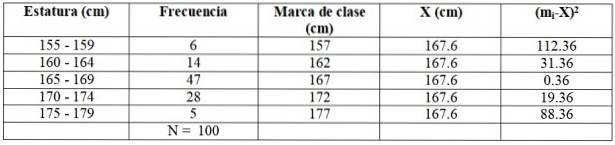
Per il nostro esempio, il voto della prima classe è (155 + 159) / 2 = 157 cm. Il lettore può vedere che i voti di classe rimanenti sono: 162, 167, 172 e 177 cm.
Determinare i voti di classe è importante, poiché sono necessari per trovare la media aritmetica e la varianza della distribuzione.
Le misure di tendenza centrale più comunemente utilizzate sono la media, la mediana e il modo, e descrivono con precisione la tendenza dei dati a raggrupparsi attorno a un certo valore centrale..
È una delle principali misure di tendenza centrale. Nei dati raggruppati, la media aritmetica può essere calcolata utilizzando la formula:

-X è la media
-Fio è la frequenza della lezione
-mio è il segno di classe
-g è il numero di classi
-n è il numero totale di dati
Per la mediana è necessario identificare l'intervallo in cui si trova l'osservazione n / 2. Nel nostro esempio, questa osservazione è il numero 50, perché ci sono un totale di 100 punti dati. Questa osservazione è compresa tra 165-169 cm.
Quindi devi interpolare per trovare il valore numerico che corrisponde a quell'osservazione, per la quale viene utilizzata la formula:
Dove:
-c = larghezza dell'intervallo in cui si trova la mediana
-BM = il limite inferiore dell'intervallo a cui appartiene la mediana
-Fm = numero di osservazioni contenute nell'intervallo mediano
-n / 2 = metà dei dati totali
-FBM = numero totale di osservazioni prima intervallo mediano
Per la modalità viene identificata la classe modale, quella che contiene il maggior numero di osservazioni, di cui si conosce il marchio di classe.
La varianza e la deviazione standard sono misure di dispersione. Se indichiamo la varianza con sDue e la deviazione standard, che è la radice quadrata della varianza come s, per i dati raggruppati avremo rispettivamente:
Y
Per la distribuzione delle altezze delle studentesse universitarie proposte all'inizio, calcolare i valori di:
a) Media
b) Mediana
c) Moda
d) Varianza e deviazione standard.
Costruiamo la seguente tabella per facilitare i calcoli:

Sostituzione di valori ed esecuzione diretta della somma:
X = (6 x 157 + 14 x 162 + 47 x 167 + 28 x 172+ 5 x 177) / 100 cm =
= 167,6 cm
L'intervallo a cui appartiene la mediana è di 165-169 cm perché è l'intervallo con la frequenza più alta.
Identifichiamo ciascuno di questi valori nell'esempio, con l'aiuto della Tabella 2:
c = 5 cm (vedere la sezione ampiezza)
BM = 164,5 cm
Fm = 47
n / 2 = 100/2 = 50
FBM = 20
Sostituendo nella formula:
L'intervallo che contiene la maggior parte delle osservazioni è di 165-169 cm, il cui voto di classe è di 167 cm.
Espandiamo la tabella precedente aggiungendo due colonne aggiuntive:
Applichiamo la formula:
E sviluppiamo la sommatoria:
SDue = (6 x 112,36 + 14 x 31,36 + 47 x 0,36 + 28 x 19,36 + 5 x 88,36) / 99 = = 21,35 cmDue
Perciò:
s = √21,35 cmDue = 4,6 cm


Nessun utente ha ancora commentato questo articolo.