Il DNA (acido desossiribonucleico) è la biomolecola che contiene tutte le informazioni necessarie per generare un organismo e mantenerne il funzionamento. È costituito da unità chiamate nucleotidi, costituite da un gruppo fosfato, una molecola di zucchero a cinque atomi di carbonio e una base azotata..
Esistono quattro basi azotate: adenina (A), citosina (C), guanina (G) e timina (T). L'adenina si accoppia sempre con la timina e la guanina con la citosina. Il messaggio contenuto nel filamento di DNA si trasforma in un RNA messaggero e questo partecipa alla sintesi delle proteine.

Il DNA è una molecola estremamente stabile, caricata negativamente a pH fisiologico, che si associa a proteine positive (istoni) per compattarsi in modo efficiente nel nucleo delle cellule eucariotiche. Una lunga catena di DNA, insieme a varie proteine associate, forma un cromosoma.
Indice articolo
Nel 1953, l'americano James Watson e il britannico Francis Crick riuscirono a delucidare la struttura tridimensionale del DNA, grazie al lavoro di cristallografia svolto da Rosalind Franklin e Maurice Wilkins. Hanno anche basato le loro conclusioni sul lavoro di altri autori.
Quando il DNA viene esposto ai raggi X, si forma un modello di diffrazione che può essere utilizzato per inferire la struttura della molecola: un'elica di due catene antiparallele che ruotano verso destra, dove entrambe le catene sono unite da legami idrogeno tra le basi. . Il pattern ottenuto è stato il seguente:

La struttura può essere assunta seguendo le leggi di diffrazione di Bragg: quando un oggetto è interposto nel mezzo di un fascio di raggi X, viene riflesso, poiché gli elettroni dell'oggetto interagiscono con il fascio..
Il 25 aprile 1953, i risultati di Watson e Crick furono pubblicati sulla prestigiosa rivista Natura, in un articolo di sole due pagine dal titolo "Struttura molecolare degli acidi nucleici", Che rivoluzionerebbe completamente il campo della biologia.
Grazie a questa scoperta, i ricercatori ricevettero il Premio Nobel per la medicina nel 1962, ad eccezione di Franklin che morì prima del parto. Attualmente questa scoperta è uno dei grandi esponenti del successo del metodo scientifico per acquisire nuove conoscenze.
La molecola di DNA è costituita da nucleotidi, unità costituite da uno zucchero a cinque atomi di carbonio attaccato a un gruppo fosfato e una base azotata. Il tipo di zucchero presente nel DNA è del tipo desossiribosio e da qui il suo nome, acido desossiribonucleico..
Per formare la catena, i nucleotidi sono legati covalentemente da un legame di tipo fosfodiestere attraverso un gruppo 3'-idrossile (-OH) da uno zucchero e il 5'-fosfofo del prossimo nucleotide.
I nucleotidi non devono essere confusi con i nucleosidi. Quest'ultimo si riferisce alla parte del nucleotide formata solo dal pentoso (zucchero) e dalla base azotata.
Il DNA è composto da quattro tipi di basi azotate: adenina (A), citosina (C), guanina (G) e timina (T).
Le basi azotate sono classificate in due categorie: purine e pirimidine. Il primo gruppo è costituito da un anello di cinque atomi attaccato ad un altro anello di sei, mentre le pirimidine sono composte da un unico anello.
Delle basi menzionate, l'adenina e la guanina derivano dalle purine. Al contrario, al gruppo delle pirimidine appartengono timina, citosina e uracile (presenti nella molecola di RNA).
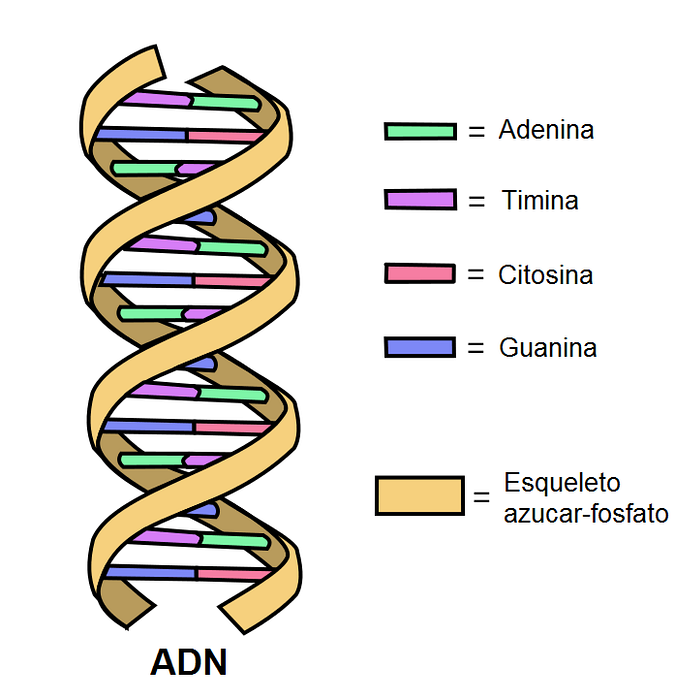
Una molecola di DNA è composta da due catene di nucleotidi. Questa "catena" è nota come filamento di DNA..
I due filamenti sono collegati da legami idrogeno tra le basi complementari. Le basi azotate sono legate in modo covalente a una spina dorsale di zuccheri e fosfati.
Ogni nucleotide situato su un filamento può essere accoppiato con un altro nucleotide specifico sull'altro filamento, per formare la ben nota doppia elica. Per formare una struttura efficiente, A si accoppia sempre con T mediante due legami idrogeno e G con C mediante tre ponti..
Se studiamo le proporzioni delle basi azotate nel DNA, troveremo che la quantità di A è identica alla quantità di T e la stessa con G e C. Questo modello è noto come legge di Chargaff.
Questo abbinamento è energeticamente favorevole, poiché consente di preservare una larghezza simile in tutta la struttura, mantenendo una distanza simile lungo la molecola dello scheletro zucchero-fosfato. Nota che una base di un anello si accoppia con una di un anello.
Si suggerisce che la doppia elica sia composta da 10,4 nucleotidi per giro, separati da una distanza da centro a centro di 3,4 nanometri. Il processo di laminazione dà luogo alla formazione di scanalature nella struttura, potendo osservare una scanalatura più grande e una più piccola.
Le scanalature sorgono perché i legami glicosidici nelle coppie di basi non sono l'uno di fronte all'altro, rispetto al loro diametro. La pirimidina O-2 e la purina N-3 si trovano nel solco minore, mentre il solco maggiore si trova nella regione opposta..
Se usiamo l'analogia di una scala, i pioli sono costituiti dalle coppie di basi complementari tra loro, mentre lo scheletro corrisponde ai due corrimano..
Le estremità della molecola di DNA non sono le stesse, motivo per cui parliamo di "polarità". Una delle sue estremità, 3 ', porta un gruppo -OH, mentre l'estremità 5' ha il gruppo fosfato libero.
I due filamenti si trovano antiparalleli, il che significa che si trovano opposti alle loro polarità, come segue:
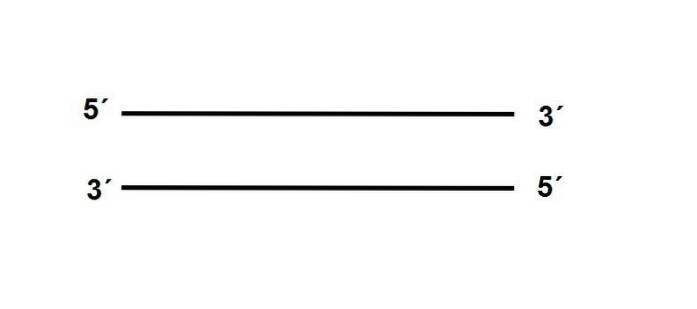
Inoltre la sequenza di uno dei trefoli deve essere complementare al suo partner, se è una posizione c'è A, nel filamento antiparallelo deve esserci una T.
In ogni cellula umana ci sono circa due metri di DNA che devono essere impacchettati in modo efficiente.
Il filo deve essere compattato in modo che possa essere contenuto in un nucleo microscopico di 6 μm di diametro che occupa solo il 10% del volume cellulare. Questo è possibile grazie ai seguenti livelli di compattazione:
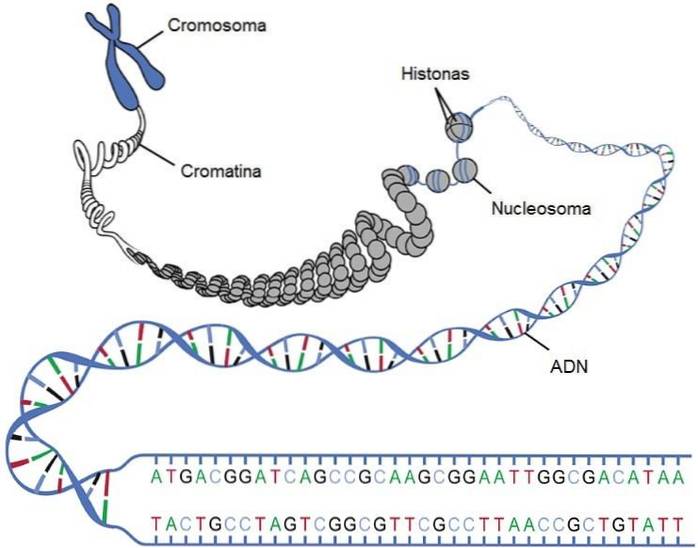
Negli eucarioti ci sono proteine chiamate istoni, che hanno la capacità di legarsi alla molecola di DNA, essendo il primo livello di compattazione del filamento. Gli istoni hanno cariche positive per poter interagire con le cariche negative del DNA, fornite dai fosfati.
Gli istoni sono proteine così importanti per gli organismi eucarioti da essere rimasti praticamente invariati nel corso dell'evoluzione, ricordando che un basso tasso di mutazioni indica che le pressioni selettive su quella molecola sono forti. Il danno agli istoni potrebbe portare a una compattazione del DNA difettosa.
Gli istoni possono essere modificati biochimicamente e questo processo modifica il livello di compattazione del materiale genetico.
Quando gli istoni sono "ipoacetilati", la cromatina è più condensata, poiché le forme acetilate neutralizzano le cariche positive delle lisine (amminoacidi caricati positivamente) nella proteina..
Il filamento di DNA si avvolge negli istoni e formano strutture che assomigliano alle perle di una collana di perle, chiamate nucleosomi. Al centro di questa struttura ci sono due copie di ogni tipo di istone: H2A, H2B, H3 e H4. L'unione dei diversi istoni è chiamata "histone octamer".
L'ottamero è circondato da circa 146 coppie di basi, che girano meno di due volte. Una cellula diploide umana contiene circa 6,4 x 109 nucleotidi organizzati in 30 milioni di nucleosomi.
L'organizzazione nei nucleosomi consente al DNA di essere compattato a più di un terzo della sua lunghezza originale.
In un processo di estrazione di materiale genetico in condizioni fisiologiche, si osserva che i nucleosomi sono disposti in una fibra di 30 nanometri.
I cromosomi sono l'unità funzionale dell'ereditarietà, la cui funzione è quella di trasportare i geni di un individuo. Un gene è un segmento di DNA che contiene le informazioni per sintetizzare una proteina (o una serie di proteine). Tuttavia, ci sono anche geni che codificano per elementi regolatori, come l'RNA.
Tutte le cellule umane (ad eccezione dei gameti e dei globuli rossi) hanno due copie di ciascun cromosoma, una ereditata dal padre e l'altra dalla madre.
I cromosomi sono strutture costituite da un lungo pezzo lineare di DNA associato ai complessi proteici sopra menzionati. Normalmente negli eucarioti tutto il materiale genetico contenuto nel nucleo è suddiviso in una serie di cromosomi.
I procarioti sono organismi privi di nucleo. In queste specie, il materiale genetico è altamente avvolto insieme a proteine alcaline a basso peso molecolare. In questo modo, il DNA viene compattato e situato in una regione centrale del batterio..
Alcuni autori chiamano spesso questa struttura "cromosoma batterico", sebbene non abbia le stesse caratteristiche di un cromosoma eucariotico.
Non tutte le specie di organismi contengono la stessa quantità di DNA. In effetti, questo valore è molto variabile tra le specie e non esiste alcuna relazione tra la quantità di DNA e la complessità dell'organismo. Questa contraddizione è nota come "paradosso del valore C".
Il ragionamento logico sarebbe quello di intuire che più complesso è l'organismo, più DNA ha. Tuttavia, questo non è vero in natura..
Ad esempio il genoma del pesce polmonare Protopterus aethiopicus Ha una dimensione di 132 pg (il DNA può essere quantificato in picogrammi = pg) mentre il genoma umano pesa solo 3,5 pg.
Va ricordato che non tutto il DNA di un organismo codifica per proteine, una grande quantità di questo è correlato a elementi regolatori e con i diversi tipi di RNA.
Il modello di Watson e Crick, dedotto dai modelli di diffrazione dei raggi X, è noto come elica B-DNA ed è il modello "tradizionale" e più conosciuto. Tuttavia, ci sono altre due forme diverse, chiamate A-DNA e Z-DNA..
La variante "A" gira a destra, proprio come il B-DNA, ma è più corta e più larga. Questa forma appare quando l'umidità relativa diminuisce.
L'A-DNA ruota ogni 11 coppie di basi, il solco maggiore è più stretto e profondo del B-DNA. Rispetto al solco minore, questo è più superficiale e largo.
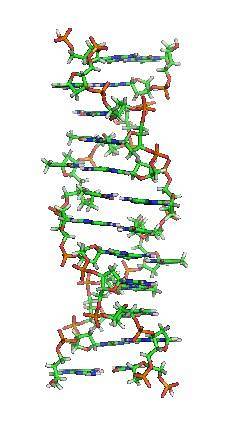
La terza variante è Z-DNA. È la forma più stretta, formata da un gruppo di esanucleotidi organizzati in un duplex di catene antiparallele. Una delle caratteristiche più notevoli di questa forma è che gira a sinistra, mentre gli altri due modi lo fanno a destra..
Lo Z-DNA appare quando ci sono brevi sequenze di pirimidine e purine che si alternano tra loro. Il solco maggiore è piatto e il minore è stretto e più profondo, rispetto al B-DNA.
Sebbene in condizioni fisiologiche la molecola di DNA sia per lo più nella sua forma B, l'esistenza delle due varianti descritte mette a nudo la flessibilità e il dinamismo del materiale genetico..
La molecola di DNA contiene tutte le informazioni e le istruzioni necessarie per la costruzione di un organismo. Viene chiamato il set completo di informazioni genetiche negli organismi genoma.
Il messaggio è codificato dall '"alfabeto biologico": le quattro basi menzionate in precedenza, A, T, G e C.
Il messaggio può portare alla formazione di vari tipi di proteine o codificare alcuni elementi regolatori. Il processo mediante il quale questi database possono recapitare un messaggio è spiegato di seguito:
Il messaggio crittografato nelle quattro lettere A, T, G e C risulta in un fenotipo (non tutte le sequenze di DNA codificano per le proteine). Per ottenere ciò, il DNA deve replicarsi in ogni processo di divisione cellulare..
La replicazione del DNA è semi-conservativa: un filamento funge da modello per la formazione della nuova molecola figlia. Diversi enzimi catalizzano la replicazione, tra cui DNA primasi, DNA elicasi, DNA ligasi e topoisomerasi..
Successivamente, il messaggio - scritto in un linguaggio di sequenza di base - deve essere trasmesso a una molecola intermedia: l'RNA (acido ribonucleico). Questo processo è chiamato trascrizione..
Affinché avvenga la trascrizione, devono partecipare diversi enzimi, inclusa la RNA polimerasi.
Questo enzima è responsabile della copia del messaggio del DNA e della sua conversione in una molecola di RNA messaggero. In altre parole, l'obiettivo della trascrizione è ottenere il messaggero.
Infine, avviene la traduzione del messaggio in molecole di RNA messaggero, grazie ai ribosomi.
Queste strutture prendono l'RNA messaggero e insieme al meccanismo di traduzione formano la proteina specificata..
Il messaggio viene letto in "terzine" o gruppi di tre lettere che specificano per un amminoacido - i mattoni delle proteine. È possibile decifrare il messaggio delle terzine poiché il codice genetico è già stato completamente rivelato.
La traduzione inizia sempre con l'amminoacido metionina, che è codificato dalla tripletta iniziale: AUG. La "U" rappresenta la base dell'uracile ed è caratteristica dell'RNA e soppianta la timina.
Ad esempio, se l'RNA messaggero ha la seguente sequenza: AUG CCU CUU UUU UUA, viene tradotto nei seguenti amminoacidi: metionina, prolina, leucina, fenilalanina e fenilalanina. Si noti che due triplette, in questo caso UUU e UUA, possono codificare lo stesso amminoacido: fenilalanina.
A causa di questa proprietà, si dice che il codice genetico sia degenerato, poiché un amminoacido è codificato da più di una sequenza di triplette, ad eccezione dell'aminoacido metionina, che determina l'inizio della traduzione..
Il processo viene interrotto con uno specifico stop o triplette di stop: UAA, UAG e UGA. Sono conosciuti rispettivamente con i nomi di ocra, ambra e opale. Quando il ribosoma li rileva, non possono più aggiungere altri amminoacidi alla catena.
Gli acidi nucleici sono di natura acida e sono solubili in acqua (idrofili). Può verificarsi la formazione di legami idrogeno tra i gruppi fosfato e i gruppi idrossilici dei pentosi con l'acqua. Ha una carica negativa a pH fisiologico.
Le soluzioni di DNA sono altamente viscose, a causa della capacità di resistenza alla deformazione della doppia elica, che è molto rigida. La viscosità diminuisce se l'acido nucleico è a filamento singolo.
Sono molecole altamente stabili. Logicamente, questa caratteristica deve essere indispensabile nelle strutture che trasportano l'informazione genetica. Rispetto all'RNA, il DNA è molto più stabile perché manca di un gruppo idrossile.
Il DNA può essere denaturato al calore, il che significa che i fili si separano quando la molecola è esposta a temperature elevate.
La quantità di calore che deve essere applicata dipende dalla percentuale G-C della molecola, perché queste basi sono legate da tre legami idrogeno, aumentando la resistenza alla separazione..
Per quanto riguarda l'assorbimento della luce, hanno un picco a 260 nanometri, che aumenta se l'acido nucleico è a filamento singolo, poiché gli anelli nucleotidici sono esposti e questi sono responsabili dell'assorbimento..
Secondo Lazcano et al. 1988 Il DNA emerge in fasi di transizione dall'RNA, essendo uno degli eventi più importanti nella storia della vita.
Gli autori propongono tre fasi: un primo periodo in cui c'erano molecole simili agli acidi nucleici, successivamente i genomi erano costituiti da RNA e come ultimo stadio apparvero i genomi del DNA a doppia banda..
Alcune prove supportano la teoria di un mondo primario basato sull'RNA. In primo luogo, la sintesi proteica può avvenire in assenza di DNA, ma non quando manca l'RNA. Inoltre, sono state scoperte molecole di RNA con proprietà catalitiche..
Per quanto riguarda la sintesi dei desossiribonucleotidi (presenti nel DNA) provengono sempre dalla riduzione dei ribonucleotidi (presenti nell'RNA).
L'innovazione evolutiva di una molecola di DNA deve aver richiesto la presenza di enzimi che sintetizzano i precursori del DNA e partecipano alla trascrizione inversa dell'RNA.
Studiando gli enzimi attuali, si può concludere che queste proteine si sono evolute più volte e che la transizione dall'RNA al DNA è più complessa di quanto si credesse in precedenza, compresi i processi di trasferimento e perdita di geni e sostituzioni non ortologhe..
Il sequenziamento del DNA consiste nel chiarire la sequenza del filamento di DNA in termini delle quattro basi che lo compongono.
La conoscenza di questa sequenza è della massima importanza nelle scienze biologiche. Può essere utilizzato per discriminare tra due specie morfologicamente molto simili, per rilevare malattie, patologie o parassiti e ha anche un'applicabilità forense.
Il sequenziamento di Sanger è stato sviluppato nel 1900 ed è la tecnica tradizionale per chiarire una sequenza. Nonostante la sua età, è un metodo valido e ampiamente utilizzato dai ricercatori.
Il metodo utilizza la DNA polimerasi, un enzima altamente affidabile che replica il DNA nelle cellule, sintetizzando un nuovo filamento di DNA utilizzando uno preesistente come guida. L'enzima richiede a primo o primer per avviare la sintesi. Il primer è una piccola molecola di DNA complementare alla molecola da sequenziare.
Nella reazione vengono aggiunti nucleotidi che verranno incorporati nel nuovo filamento di DNA dall'enzima.
Oltre ai nucleotidi "tradizionali", il metodo include una serie di dideoxynucleotides per ciascuna delle basi. Differiscono dai nucleotidi standard per due caratteristiche: strutturalmente non consentono alla DNA polimerasi di aggiungere più nucleotidi al filamento figlia e hanno un marker fluorescente diverso per ciascuna base.
Il risultato è una varietà di molecole di DNA di diverse lunghezze, poiché i dideoxinucleotidi sono stati incorporati in modo casuale e hanno interrotto il processo di replicazione in fasi diverse..
Questa varietà di molecole può essere separata in base alla loro lunghezza e l'identità dei nucleotidi viene letta mediante l'emissione di luce dall'etichetta fluorescente..
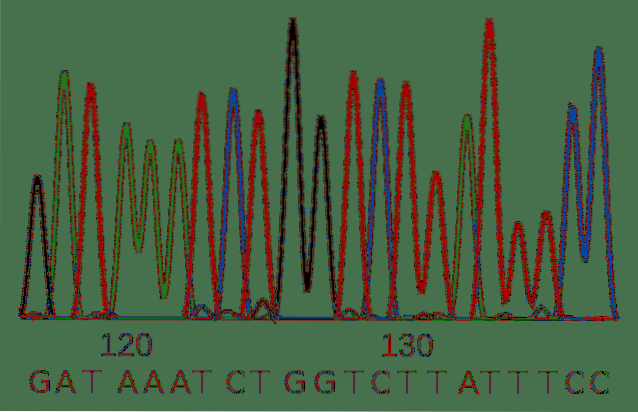
Le tecniche di sequenziamento sviluppate negli ultimi anni consentono un'analisi massiccia di milioni di campioni simultaneamente.
Tra i metodi più eccezionali vi sono il pirosequenziamento, il sequenziamento per sintesi, il sequenziamento per legatura e il sequenziamento di nuova generazione mediante Ion Torrent..



Nessun utente ha ancora commentato questo articolo.